Drzewo trie (czyt. tri lub traj) to struktura danych wykorzystywana w algorytmach tekstowych, która umożliwia efektywne przechowywanie i wyszukiwanie zestawu ciągów znaków, takich jak słowa lub frazy. Jego nazwa pochodzi od słowa "retrieval" (odzyskiwanie), ponieważ jego głównym celem jest szybkie odnajdywanie przechowywanych wzorców.
Drzewa trie są szczególnie użyteczne w sytuacjach, gdy konieczne jest wielokrotne wyszukiwanie wzorców w dużym zbiorze danych tekstowych. W takich przypadkach przewyższają klasyczne algorytmy wyszukiwania, takie jak Knuth-Morris-Pratt (KMP) czy Boyer-Moore (BM), zwłaszcza gdy tekst wejściowy zawiera dużą liczbę słów. Trie stanowią także podstawę dla bardziej zaawansowanych struktur danych, takich jak drzewa sufiksowe.
Podstawy i budowa drzewa trie
Drzewo trie jest drzewem, w którym każdy węzeł reprezentuje pojedynczy znak. Ścieżka od korzenia drzewa do danego węzła opisuje pewien prefiks (początkowy fragment) jednego lub więcej ciągów znaków. Najważniejsze cechy tej struktury to:
- hierarchiczne przechowywanie danych: Każdy poziom drzewa odpowiada kolejnym znakom ciągów znaków,
- współdzielenie prefiksów: Różne ciągi znaków, które mają wspólny początek, dzielą te same węzły, co redukuje redundancję i oszczędza miejsce,
- znakowanie końców słów: Węzły mogą zawierać specjalne oznaczenie (np. flaga logiczna), wskazujące, że dana ścieżka kończy się na pełnym słowie.
Przykład
Załóżmy, że chcemy przechować zestaw słów: cat, car, cart, dog, dove.
Drzewo trie zbudowane dla tego zbioru wygląda następująco:
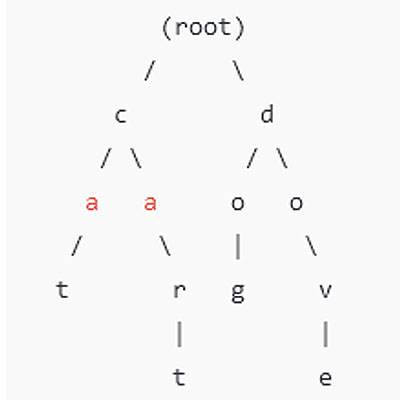
Każda ścieżka od korzenia do liścia reprezentuje słowo: cat, car, cart, dog, dove.
Operacje na drzewach trie
Drzewa trie umożliwiają wykonywanie różnych operacji na przechowywanych danych, takich jak dodawanie, wyszukiwanie i usuwanie ciągów znaków. Wszystkie te operacje działają w czasie proporcjonalnym do długości słowa, niezależnie od liczby słów w drzewie.
1. Dodawanie słowa
Aby dodać słowo do drzewa trie
- rozpoczynamy od korzenia;
- dla każdego znaku w słowie:
- jeśli węzeł odpowiadający znakowi istnieje, przechodzimy do niego;
- jeśli nie istnieje, tworzymy nowy węzeł;
- po dodaniu wszystkich znaków oznaczamy ostatni węzeł jako końcowy dla tego słowa.
2. Wyszukiwanie słowa
Wyszukiwanie polega na iteracyjnym przechodzeniu przez węzły odpowiadające kolejnym znakom słowa. Jeśli uda się przejść przez całą długość słowa, a ostatni węzeł jest oznaczony jako końcowy, oznacza to, że słowo istnieje w drzewie.
3. Usuwanie słowa
Usuwanie słowa wymaga:
- znalezienia ścieżki odpowiadającej słowu;
- usunięcia węzłów tylko wtedy, gdy nie są one częścią innego słowa.
Zalety i wady drzewa trie
Zalety
- Szybkie wyszukiwanie - czas wyszukiwania zależy wyłącznie od długości szukanego słowa, a nie od liczby przechowywanych elementów.
- Efektywne przechowywanie prefiksów - współdzielenie węzłów redukuje redundancję danych.
- Wsparcie dla operacji prefiksowych - trie umożliwia łatwe znajdowanie wszystkich słów zaczynających się od danego prefiksu.
Wady
- Duże zużycie pamięci - węzły w drzewie mogą zajmować dużo miejsca, szczególnie gdy słowa nie mają wspólnych prefiksów.
- Kosztowna inicjalizacja - tworzenie drzewa trie może być czasochłonne w przypadku dużych zbiorów danych.
Zastosowania drzew trie
Drzewa trie znajdują zastosowanie w wielu dziedzinach informatyki i technologii, poniżej kilka przykładów.
- Sprawdzanie poprawności pisowni - trie przechowuje słownik i umożliwia szybkie sprawdzenie, czy dane słowo istnieje w zbiorze.
- Autouzupełnianie tekstu - dzięki operacjom na prefiksach, trie pozwala na szybkie znalezienie wszystkich słów zaczynających się od podanego ciągu znaków.
- Wyszukiwanie wzorców - trie jest podstawą bardziej zaawansowanych struktur, takich jak drzewa sufiksowe, które umożliwiają efektywne wyszukiwanie wzorców w tekście.
- Kompresja danych - w niektórych algorytmach trie służy do kompresji ciągów znaków przez eliminację redundancji.
Rozszerzenia - drzewa sufiksowe i tablice sufiksowe
Drzewa trie stanowią podstawę do budowy bardziej zaawansowanych struktur, takich jak drzewa sufiksowe. Drzewo sufiksowe to trie zbudowane dla wszystkich sufiksów danego tekstu. Struktura ta umożliwia szybkie wyszukiwanie podciągów w tekście oraz realizację operacji, takich jak znajdowanie najdłuższego wspólnego prefiksu.
Trie to wszechstronna i efektywna struktura danych, szczególnie przydatna w zadaniach związanych z tekstem i ciągami znaków. Chociaż ich inicjalizacja i przechowywanie mogą być kosztowne pod względem pamięci, szybkość wyszukiwania oraz możliwość obsługi operacji prefiksowych sprawiają, że są niezastąpione w wielu zastosowaniach, od wyszukiwarek internetowych po systemy poprawności pisowni. Zrozumienie podstaw działania trie otwiera drogę do eksploracji bardziej zaawansowanych technik algorytmicznych.
Komentarze